导出豆瓣已看电影数据并导入到trakt
豆瓣并没有导出数据的选项,要用python爬虫抓取相关数据,用letterboxd作为跳板,最终导入trakt。
对于豆瓣的现状,我理解有不可抗力的原因,作为用户只能选择搬走属于自己的数据另找他处。
需求
由于letterboxd仅支持电影,所以这种方法无法转移电视剧的观看数据。但由于我早就开始用trakt追剧了,故影响不大。
导出豆瓣数据到csv
需要python 3的环境,我用的是conda进行环境管理,如何安装conda。
1 | conda create -n py3 python=3.8 |
浏览器访问豆瓣主页,F12调出开发者工具 > Network > 搜索douban > 选择www.douban.com > 有边栏Headers找到Cookie > 右键Copy Value。
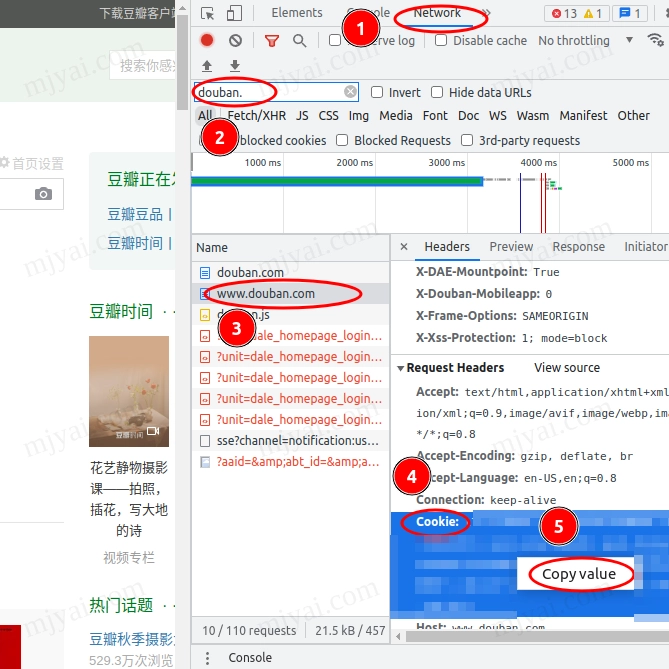
编辑douban_to_csv.py,将复制的内容粘贴到COOKIES = {'cookie':''}中的两个单引号之间。保存。
1 | python douban_to_csv.py <user_id> [yyyymmdd] |
[user_id]为豆瓣的用户 ID,查找方法参见:如何查找自己的豆瓣 ID
[yyyymmdd]为爬取的开始日期,即大于(不包含)该日期的电影评分才会被爬取。
豆瓣加了反爬机制,没有cookies抓10页,加了cookie可抓30页左右。之后会报错无法获得IMDB编号的电影页面:甚至TypeError: 'NoneType' object is not iterable,此时记下已抓取的页数。
编辑douban_to_csv.py,将START_PAGE的值从1改成已抓取的页数。
浏览器访问豆瓣主页,会显示有异常请求从你的 IP 发出,点击通过人机测试。
再次执行前面的命令,会从该页继续抓取。如此反复直至抓取完毕。得到movie.csv文件。
数据导入letterboxd
需要先将movie.csv中的数据按letterboxd的导入数据格式添加数据头,而且letterboxd一次导入最多1800条,超过浏览器会崩溃,报错SIGKILL。
1 | python csv_to_letterboxd.py |
此时会将原始数据分割成若干csv文件。
letterboxd导入为list会忽略WatchedDate,所以应该直接在帐号设置中导入。
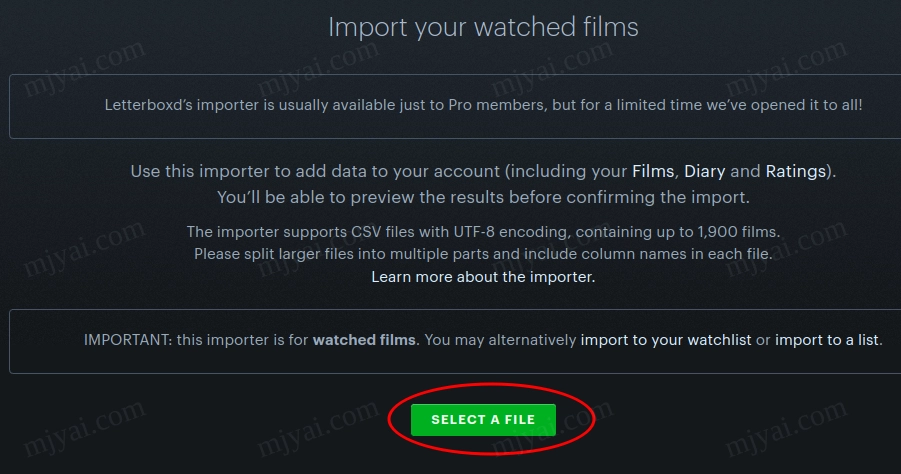
导出letterboxd数据
访问IMPORT & EXPORT,点击EXPORT YOUR DATA获得zip压缩包。
解压后watched.csv就是我们下一步需要的数据。
数据导入trakt
导入用trakt—letterboxd-import,另外我还顺便解决了其对中文支持不佳的问题。
1 | git clone https://github.com/jensb89/trakt---letterboxd-import.git |
需要先去这里建立一个新的trakt应用,点击绿色的NEW APPLICATION。随便填个名字,Redirect uri填urn:ietf:wg:oauth:2.0:oob,点SAVE APP
记下Client ID,Client Secret,点击Redirect URI处绿色的Authorize按钮,记下PIN。
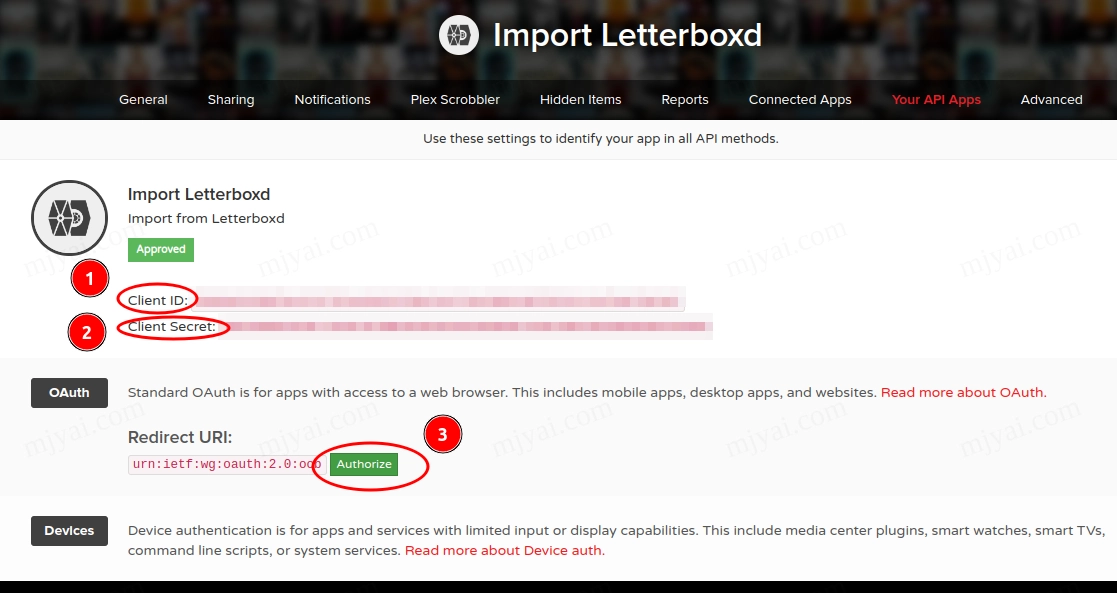
编辑py-trakt-letterboxd-import.py ,填入刚才记下的三个值,其中CODE就是PIN。
执行导入程序。
1 | python py-trakt-letterboxd-import.py --watched watched.csv |