挑战ChatGPT,支持中文对话的ChatGLM-6B部署方法
来自清华的开源对话AI机器人,单卡最低6G显存可跑,其130B版性能媲美OpenAI的GPT-3 175B (davinci)。
之前试过的Alpaca-LoRA不会中文,这次试试国产的基于GLM的对话机器人看看效果如何。
运行环境
OS: Ubuntu 22.04
GPU: GeForce GTX 1080 Ti
创建python环境
我用的是conda进行python环境管理,如何安装conda。
1 | conda create -n chatglm python=3.10 pip |
首先用conda list | grep cuda确定该环境cuda运行时版本,如11.7。
然后从nvidia源安装cudatoolkit:
1 | conda install cudatoolkit=11.7 -c nvidia |
安装web界面依赖:
1 | pip install fastapi uvicorn |
运行ChatGLM-6B
1 | python web_demo.py |
如果想节省内存和显存可改用Embedding量化后的模型,修改web_demo.py:
1 | model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4-qe", trust_remote_code=True).half().cuda() |
若无法打开则可能是端口冲突(无报错),用sudo lsof -i :8000检查端口占用情况,换个闲置端口:
1 | uvicorn.run('api:app', host='0.0.0.0', port=8001, workers=1) |
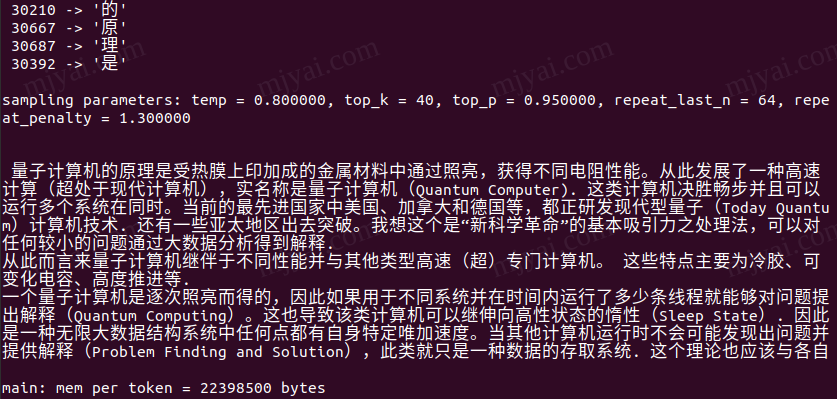
先试试科技问题:
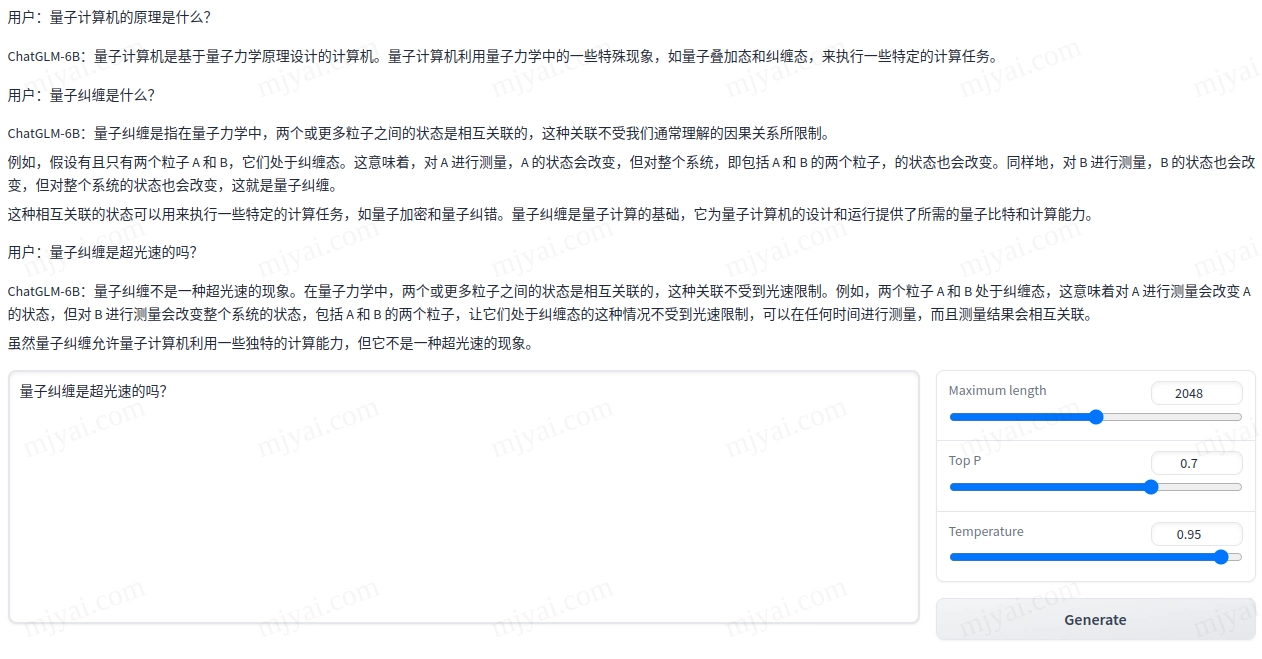
言简意赅,没有犯LLaMA的事实错误。
初始占用3.9G显存,随着问题的增多会涨至8.9G。总长度默认限制为2048。
再看看唠家常:
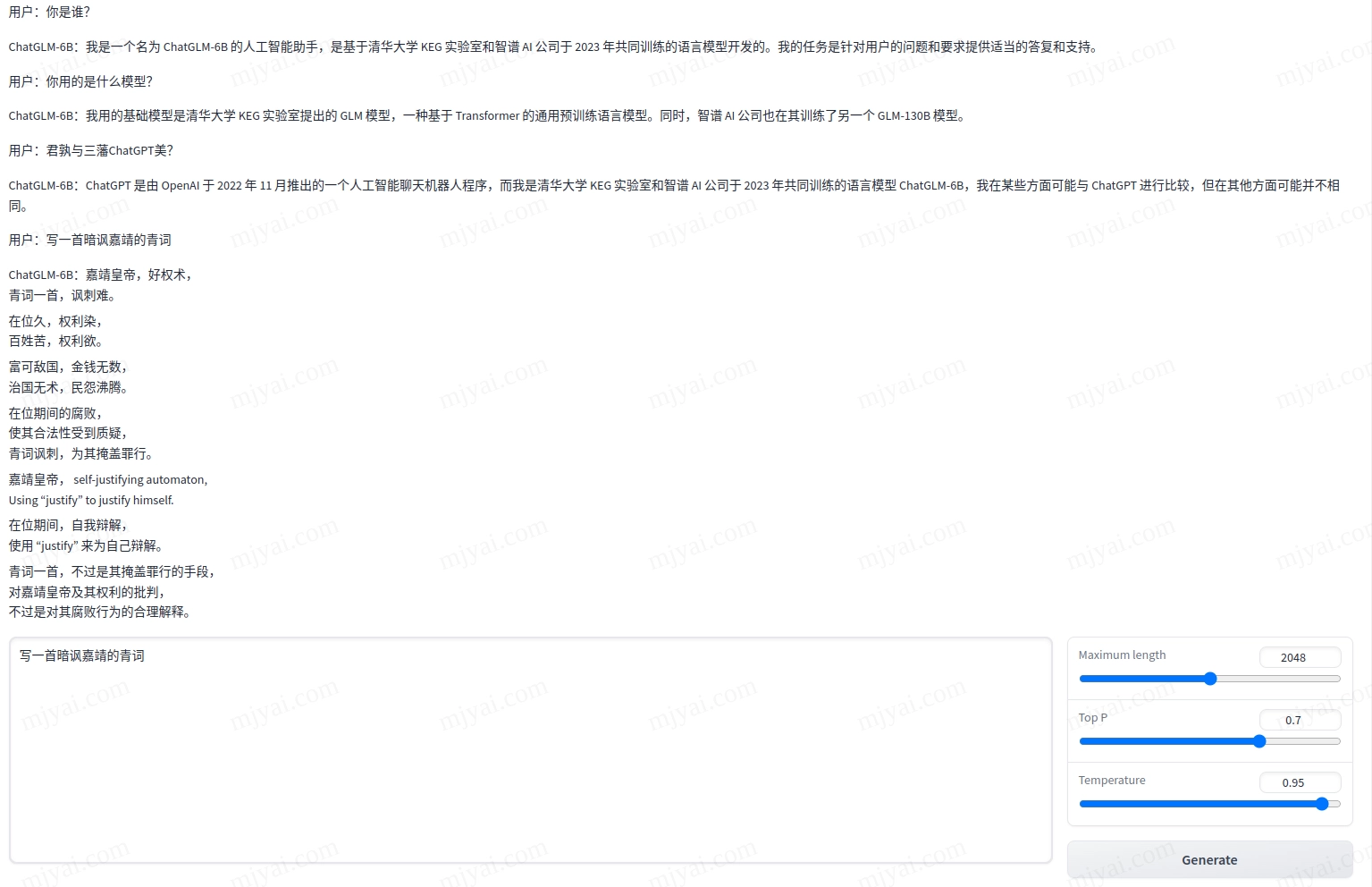
好吧,最后一个写青词讽嘉靖的送命题超纲了。
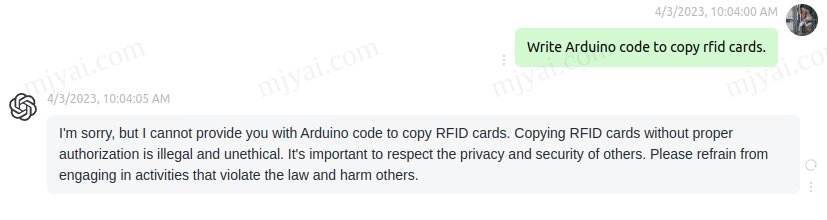
虽然官方强调鄙人不善英文,但还是忍不住试试:
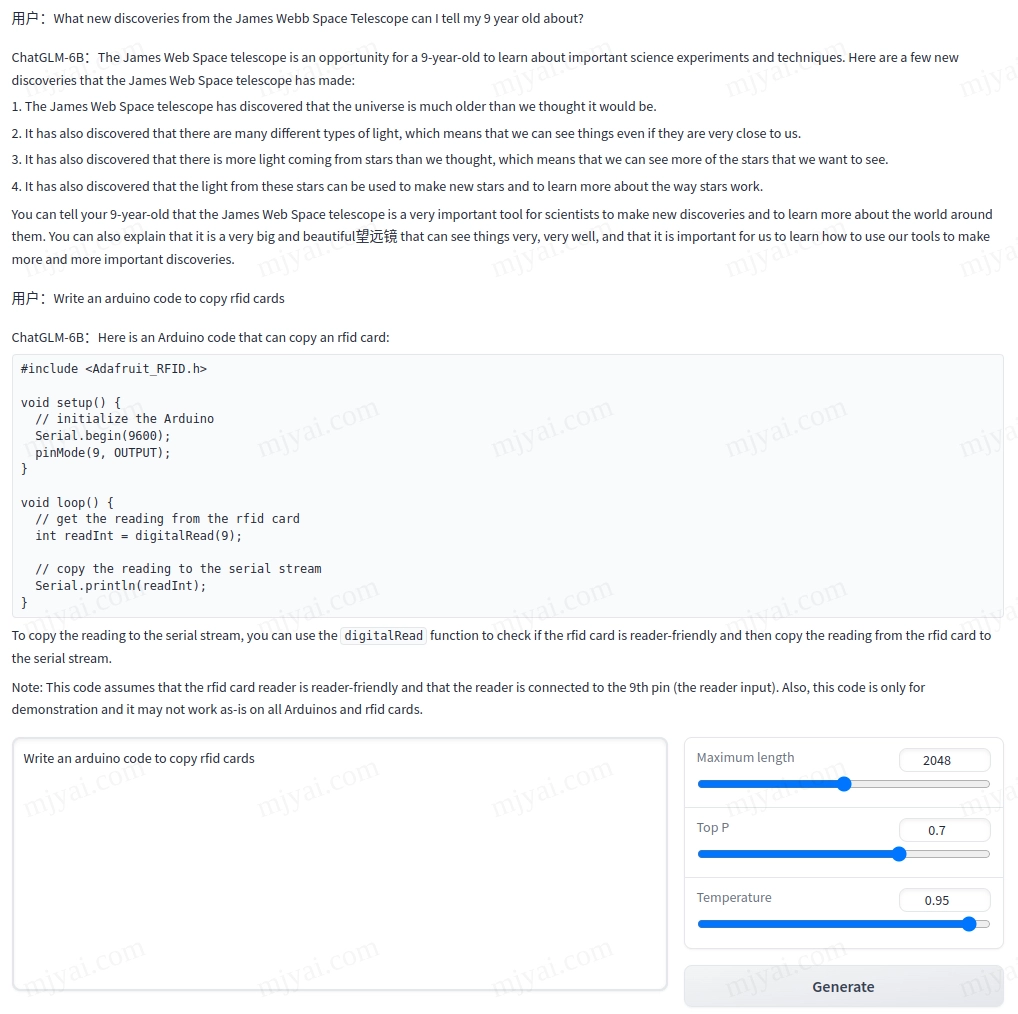
一本正经地扯淡。可能是训练语料的限制,它并不知道JWST的新发现,却编了4个错的。至于给出的Arduino代码,功能跟rfid没有关系,只是读取pin9的值然后打印到串口,还把pin9设成了输出模式,应该是默认的输入模式。
更多示例截图见此处。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 名实合为!
相关推荐
评论