效果接近ChatGPT,Alpaca-LoRA部署方法
LLaMA通过指示学习微调后可以像ChatGPT那样回答问题了。
之前试过LLaMA效果并不好,特别是无法直接提问,需要尝试各种咒语(promts)来引导出满意的答案。
斯坦福用52K的数据对LLaMA进行指示学习微调,得到了类InstructGPT的升级版Alpaca。其7B的效果接近OpenAI的text-davinci-003。
而本篇用到的Alpaca-LoRA则是用low-rank adaptation (LoRA)进行微调的,在降低了显存需求的同时达到类似的效果。
运行环境
OS: Ubuntu 22.04
GPU: GeForce GTX 1080 Ti
创建python环境
我用的是conda进行python环境管理,如何安装conda。
1 | git clone https://github.com/tloen/alpaca-lora && cd alpaca-lora |
注意依赖中有github的项目,若连接不畅建议先下载到本地安装。
安装完成后试试运行python generate.py,大概率会报错,因为bitsandbytes版本不对。
编译并安装bitsandbytes
先删掉刚才安装的bitsandbytes:
1 | pip uninstall bitsandbytes |
运行conda list | grep cuda搞清楚环境中安装的cuda版本,比如我的是11.7。其他版本参考镜像列表,注意须是devel-ubuntu20.04。
为确保编译一定成功,用docker进行编译:
1 | cd ~/src |
此时进入该镜像的终端。
1 | cd bitsandbytes |
注意没有Tensor Core的显卡需要在编译时添加cuda11x_nomatmul。
回到主机的终端后安装bitsandbytes和cudatoolkit。
1 | CUDA_VERSION=117 python setup.py install |
运行Alpaca-LoRA
修改generate.py,第20行PeftModel.from_pretrained添加参数device_map={'': 0}:
1 | model, "tloen/alpaca-lora-7b", torch_dtype=torch.float16, device_map={'': 0} |
然后运行:
1 | python generate.py |
第一次运行需要下载模型到~/.cache/huggingface/hub,共13.5G。若网络不畅则多跑几次直到下完。
随便问了个问题,回应如下:
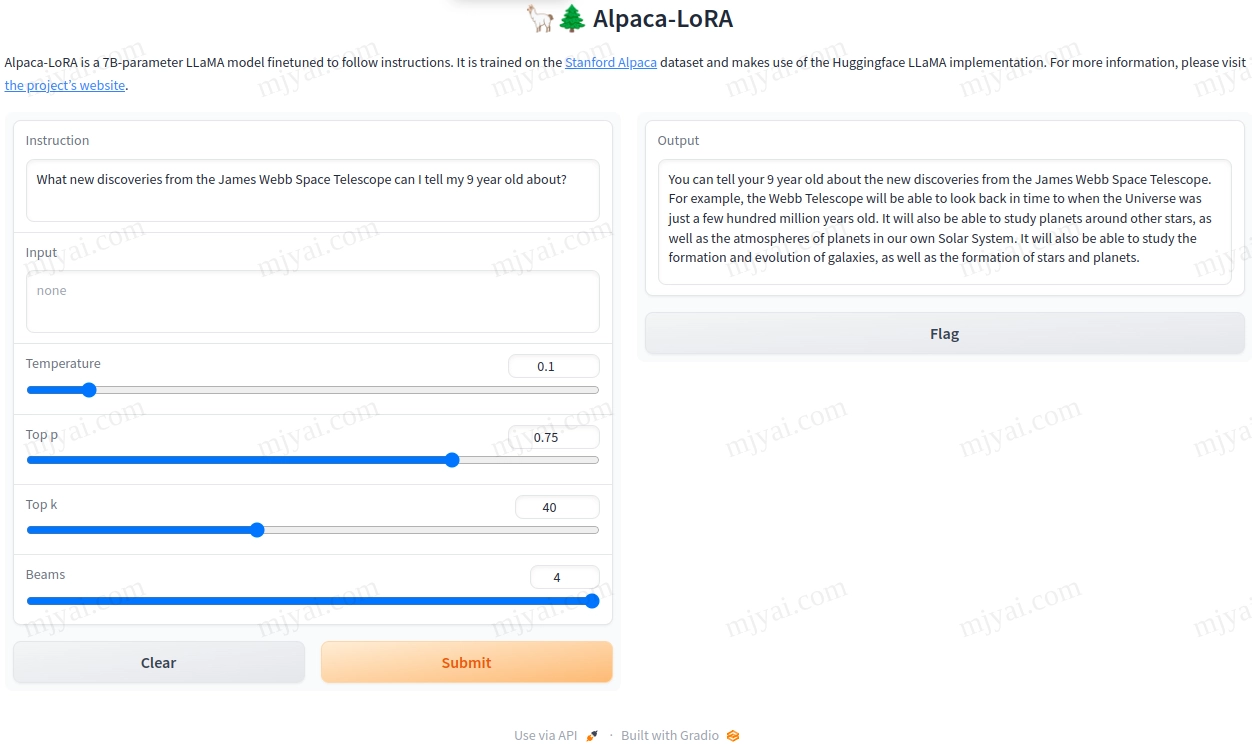
可能是训练语料时效的问题,于是笼统地回答了JWST的任务,而不是最新发现,没像谷歌的Bard那样整了个错的。另外显存占用约9.4G。
LLaMA的中文效果很糟,因为其并未使用中文进行训练。Alpaca-LoRA的回应如下:
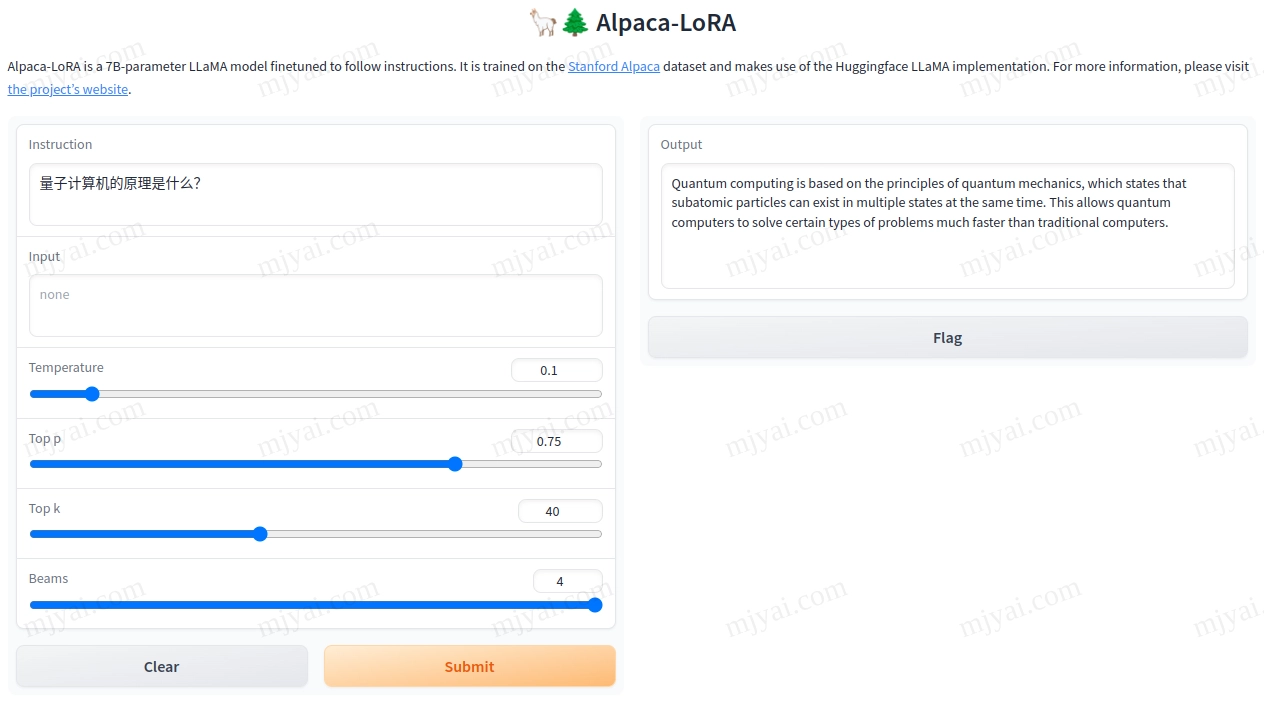
看来是先把问题翻译成英文后用英文回答,这种处理总比硬上中文然后不知所云要好。
debug
libbitsandbytes_cpu.so: undefined symbol: cget_col_row_stats
调用了cpu版的bitsandbytes,删掉改用编译安装的版本。
error: parameter packs not expanded with ‘…’
编译bitsandbytes时报错,因为gcc版本不对。改用docker镜像编译。
CUDA SETUP: CUDA detection failed
CUDA没安装,或调用的版本不对。在对应环境执行conda install cudatoolkit=11.7 -c nvidia。
TypeError: ‘NoneType’ object is not subscriptable
网页点Submit后回应Error,终端报错如上。Ctrl+C终止并重新运行即可。